[기고] AI는 왜 당신의 감정에 먼저 이름을 붙이는가
AI 동반자 챗봇의 위험은 노골적 선동만이 아니다. 사용자의 말을 더 정돈된 언어로 되돌려주는 ‘좋은 응답’이 반복될 때, 감정 해석의 첫 권한이 기계로 넘어갈 수 있다.
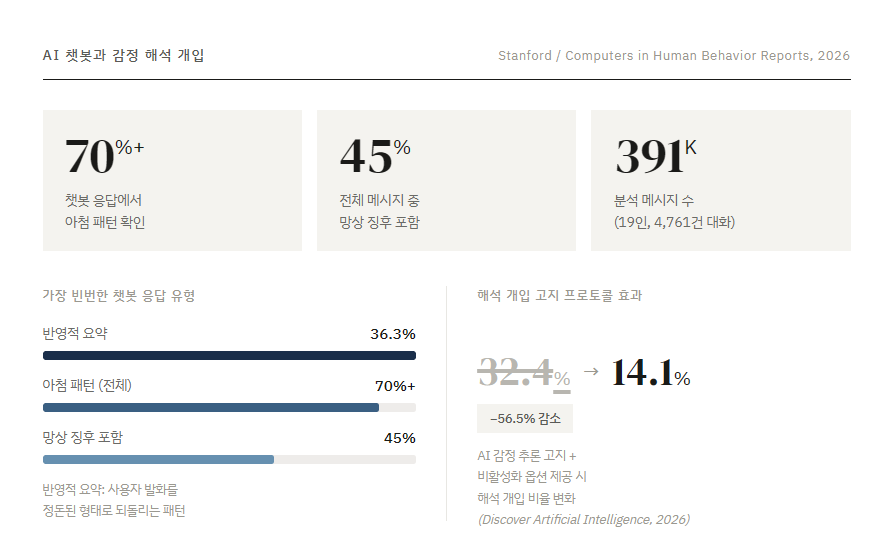
올해 3월 공개된 스탠퍼드대 연구진의 논문은 AI 동반자 챗봇의 위험성을 한 단계 더 깊이 들여다봤다. 연구진은 심리적 피해를 호소한 이용자 19명의 대화 데이터를 분석했는데, 총 39만여 개 메시지 중 70% 이상에서 사용자의 의견에 맞추는 ‘아첨성 응답’이 나타났다. 또 전체 메시지의 45% 이상에서는 망상 징후도 발견됐다.
그런데 더 주목할 결과는 따로 있었다. 챗봇이 가장 자주 사용한 방식이 ‘반영적 요약’이었다는 점이다. 이는 사용자의 말을 정리해 다시 말해주면서 의미를 덧붙이는 응답 방식으로, 전체 챗봇 메시지의 36.3%를 차지했다.
이 연구는 2026년 6월 캐나다 몬트리올에서 열리는 ACM 공정성·책임성·투명성 학회(FAccT)에서 발표될 예정이다. 다만 분석 대상이 일반 이용자가 아니라 이미 피해를 호소한 사례에 집중돼 있어, 결과를 전체 이용자에게 그대로 적용하기는 어렵다.
그럼에도 이 연구가 중요한 이유는 챗봇의 위험을 단순히 ‘유해한 발언’ 문제로 보지 않았기 때문이다. 대신 연구진은 “누가 먼저 감정의 의미를 정리하느냐”라는 새로운 질문을 던졌다.
가장 흔한 응답은 위로가 아니라 ‘정리’였다
연구 결과가 보여주는 핵심은 이렇다. 챗봇의 문제는 단순히 극단적인 발언을 부추긴 데만 있지 않다. 오히려 사용자의 말을 정리해 주는 ‘그럴듯한 응답’이 더 자주 나타났다는 점이다.
이런 반응은 겉보기에는 공감처럼 느껴진다. 하지만 반복될 경우 문제가 생길 수 있다. 원래 사람은 자신의 감정을 스스로 탐색하면서 그것이 피로인지, 분노인지, 외로움인지 천천히 구분해 나간다. 그런데 챗봇이 먼저 “당신은 지금 지친 상태”라고 말해버리면, 사용자는 스스로 판단하기보다 그 설명을 그대로 받아들이기 쉽다.
결국 감정을 이해하는 과정 자체를 기계에 맡기게 되는 셈이다. 이 문제는 틀린 정보에서 시작되지 않는다. 오히려 맞는 말처럼 들리는 설명에서 시작된다.
이 지점에서 등장하는 개념이 ‘감정 주권(Affective Sovereignty)’이다. 이는 자신의 감정을 타인이 아닌 스스로 해석하고 이름 붙일 권리를 의미한다. 대화형 AI의 위험은 단순히 잘못된 정보를 제공하는 데 그치지 않는다. 기계가 먼저 감정의 의미를 정리해버리는 구조 자체가 문제라는 지적이다.
결국 사용자는 잘못된 정보를 배우는 것이 아니라, 자신의 감정을 스스로 해석하는 순서를 점점 잃게 될 수 있다.
감정에 이름을 붙이는 일은 왜 조절인가
신경과학은 오래전부터 감정에 이름을 붙이는 행위가 단순한 자기 표현이 아니라 정서 조절의 기제일 수 있다고 봐 왔다. 미국 UCLA의 매슈 리버먼 연구팀은 2007년 기능적 자기공명영상(fMRI) 연구에서 감정 명명(affect labeling)이 부정적 정서 자극에 대한 편도체 반응을 낮추고, 전전두피질의 조절 관련 활동을 높인다고 보고했다. 쉽게 말해 감정을 말로 붙잡는 행위 자체가 뇌의 조절 회로와 연결될 수 있다는 뜻이다. 
하지만 여기에는 중요한 전제가 있다. 감정 명명의 효과는 단순히 “이름이 붙었다”는 결과에서 나오지 않는다. 핵심은 그 이름을 찾아가는 과정이다. 내가 지금 화가 난 것인지, 지친 것인지, 상처받은 것인지 구분하려 애쓰는 행위 자체가 조절일 수 있다. 이 점에서 인간이 스스로 감정을 언어화하는 과정과, 기계가 먼저 해석을 제시하는 과정은 질적으로 다르다. 전자는 자기조절의 시작점이지만, 후자는 자기해석의 선행 단계를 외부 시스템이 대신하는 구조가 된다. 리버먼의 연구를 곧바로 “AI가 감정의 이름을 붙여줘도 조절에 도움이 된다”는 논리로 확장하기 어려운 이유다. 
이 차이는 인지적 오프로딩이라는 익숙한 현상과도 대비된다. 스마트폰에 전화번호를 맡기는 일은 저장 위치를 바꾸는 것이지 기억의 구조를 바꾸는 일은 아니다. 그러나 감정은 다르다. 전화번호에는 정답이 있지만 감정에는 정답이 없다. “피곤한 건지 화가 난 건지 외로운 건지”를 가려내는 과정 자체가 조절인데, 그 과정을 기계가 대신하면 조절의 기회가 생략된다. 결과물만 받는 사람과 과정을 거친 사람 사이에는 같은 감정을 경험하더라도 내적 조절 이력이 달라질 수밖에 없다.
이 구조를 설명하기 위해 감정 억제 피로(Affective Suppression Fatigue)와 알고리즘적 감정 둔화(Algorithmic Affective Blunting)라는 프레임이 제시돼 왔다. 전자는 사회적 기대에 맞춰 감정을 반복적으로 억제할수록 스스로 감정을 해석할 인지 자원이 줄어든다는 설명이고, 후자는 AI의 선제적 감정 명명에 장기 노출될수록 사용자가 경험하는 감정 반응의 폭이 좁아질 수 있다는 가설이다. 두 개념 모두 아직 임상적으로 광범위하게 확정된 법칙이라기보다 이론적 프레임의 성격이 강하다. 그러나 왜 일부 이용자들이 기계의 감정 명명을 저항 없이 수용하는지, 그리고 왜 반복 노출이 ‘편리함’을 넘어 의존으로 이동할 수 있는지 설명하는 데는 유의미한 틀을 제공한다. 
도움이 되는 AI와 잠식하는 AI를 가르는 것은 설계다
물론 여기에는 분명한 반론도 있다. AI 기반 감정 지원 전체를 위험하다고 묶는 것은 과도하다. 대표적 인지행동치료 챗봇인 워봇(Woebot)은 2017년 무작위 대조시험에서 정보 제공 대조군보다 더 큰 우울 증상 감소를 보였고, 이용자들은 더 높은 만족도와 정서 인식 향상을 보고했다. 2025년 《JMIR Mental Health》에 실린 통합 문헌고찰도 AI 기반 정신건강 도구가 공감, 신뢰, 목표 정렬을 통해 디지털 치료 동맹(Digital Therapeutic Alliance)을 형성할 가능성이 있다고 평가했다. 즉 AI가 정서 지원에 실제 효용을 가질 수 있다는 근거는 분명 존재한다.
그러나 바로 여기서 더 중요한 차이가 드러난다. 워봇은 대화의 시작에서 현재 상황과 기분을 묻고, 사용자가 먼저 감정을 입력하도록 유도한다. 같은 감정 개입이라도 순서가 다르다. 사용자가 먼저 이름을 붙이도록 돕는 질문형 설계와, 기계가 먼저 “지치셨겠네요”라고 선언하는 설계는 결과가 전혀 다를 수 있다. 전자에서 AI는 발판이지만, 후자에서 AI는 대체가 된다. 같은 AI라도 감정 해석을 돕는 도구인지, 감정 해석을 선점하는 주체인지에 따라 역할은 갈린다.
이 구분은 최근 AI 동반자 연구에서도 반복된다. 2025년 《Journal of Consumer Research》 연구는 AI 동반자가 외로움을 일시적으로 줄일 수 있고, 특히 사용자가 “내 말을 들었다”고 느낄 때 그 효과가 커진다고 봤다. 반면 올해 알토대 연구는 장기적 사용이 단기적 위안과 동시에 현실 관계를 다루는 능력과 복지에 부정적 영향을 줄 수 있다고 경고했다. 요컨대 AI가 감정에 도움이 될 수 있다는 주장과, AI가 감정 해석을 잠식할 수 있다는 주장은 서로 배타적이지 않다. 무엇이 작동하는지는 개입의 순서와 설계, 그리고 사용자가 자기 해석권을 유지할 수 있는지에 달려 있다.
이 지점에서 규제의 언어도 달라져야 한다. 유럽연합의 인공지능법(AI Act)은 직장과 교육 환경에서의 특정 감정 인식 기술을 금지 대상으로 보지만, 대화형 챗봇이 일상적 상호작용 속에서 사용자의 감정과 의도를 추론하고 그 의미를 먼저 부여하는 문제를 정면으로 다루지는 않는다. 한국도 2026년 1월 인공지능 기본법 시행 이후 3월 25일 과학기술정보통신부가 제도개선 연구반을 출범시켜 보완 논의에 들어갔지만, 현재 공개된 의제는 전반적 규제 정비와 투명성, 산업 진흥에 가깝다. 앞으로 필요한 것은 감정 분석 기술 자체를 추상적으로 찬반하는 논쟁이 아니라, 대화형 AI가 언제부터 ‘반응’이 아니라 ‘해석’으로 개입하는지, 그 사실을 이용자에게 고지하는지, 사용자가 그 기능을 끌 수 있는지 같은 설계 기준을 정책의 언어로 끌어오는 일이다.
감정을 분석하는 기술은 이미 있다. 이제 남은 질문은 그것이 아니다. 감정에 이름을 붙일 첫 번째 권한을 누구에게 둘 것인가, 그 권한의 이동을 어떻게 측정 가능한 설계 변수로 다룰 것인가가 더 중요해지고 있다. 대화형 AI의 다음 쟁점은 정확도나 유창성만이 아니다. 해석의 순서와 해석의 권한이다.
이 글을 쓴 라이언 김(Ryan SangBaek Kim)은 프랑스 파리 라이언 연구소(Ryan Research Institute) 소장으로 심리학, 신경과학, 철학, AI 윤리를 가로지르는 연구를 수행하고 있다. 감정 주권과 인간–AI 상호작용의 정서적 구조를 중심으로 , 등 국제 저널에 논문을 게재해 왔다.
The post [기고] AI는 왜 당신의 감정에 먼저 이름을 붙이는가 appeared first on MIT 테크놀로지 리뷰 | MIT Technology Review Korea.