AI 챗봇, 개인 전화번호까지 노출…프라이버시 경고음
구글 AI가 개인 연락처 정보를 노출했다는 사례가 이어지고 있지만, 문제는 이를 막을 뚜렷한 방법이 없다는 것이다.
구글의 생성형 AI가 이용자의 개인 연락처를 노출했다는 사례가 잇따르고 있다. 문제는 이를 사전에 차단할 방법이 사실상 없다는 점이다.
최근 미국의 온라인 커뮤니티 플랫폼 레딧(Reddit)에서는 한 이용자가 “도움이 절실하다”며 “한 달 가까이 낯선 사람들의 전화를 계속 받고 있다”고 호소했다. 그는 “모르는 사람들이 변호사나 제품 디자이너, 열쇠 수리공을 찾는다며 연락해 왔는데, 구글의 생성형 AI가 이용자들에게 전화번호를 잘못 안내해서 엉뚱한 전화가 오는 것 같다”고 덧붙였다.
비슷한 사례는 다른 지역에서도 확인되고 있다. 지난 3월에는 이스라엘의 한 소프트웨어 개발자가 “구글 챗봇 제미나이가 고객 지원 안내 과정에서 자신의 전화번호를 잘못 포함시키는 바람에 왓츠앱(WhatsApp) 메시지를 받았다”고 밝혔다. 이어 4월에는 워싱턴대학교의 한 박사과정 연구원이 제미나이를 테스트하던 중 동료의 개인 휴대전화 번호가 응답으로 노출되는 일을 겪기도 했다.
이 같은 사례는 생성형 AI의 개인정보 위험이 더 이상 이론에 머물지 않는다는 점을 보여준다. AI 연구자와 개인정보 보호 전문가들이 오래전부터 경고해 온 우려가 실제 사례로 드러나고 있는 것이다. 다만 레딧 이용자의 사례는 독립적으로 검증되지는 않았고, 당사자 역시 추가 취재 요청에 응답하지 않았다.
전문가들은 원인으로 학습 데이터에 포함된 개인식별정보(PII)를 지목한다. 다만 실제 전화번호가 어떤 경로를 거쳐 모델 응답에 포함되는지 구체적인 메커니즘은 아직 명확히 밝혀지지 않았다. 이유가 무엇이든 피해를 입는 개인에게는 상당한 부담이 될 수밖에 없다. 더 큰 문제는 이를 효과적으로 막을 수 있는 수단이 아직 마련되지 않았다는 점이다.
AI 관련 개인정보 삭제 요청 급증
AI 챗봇이 개인 전화번호를 얼마나 자주 노출하는지는 정확히 파악하기 어렵지만 전문가들은 실제 발생 규모가 공개된 사례보다 훨씬 클 것으로 보고 있다.
이 같은 우려는 수치로도 확인된다. 온라인 개인정보 삭제 서비스를 제공하는 딜리트미(DeleteMe)에 따르면 생성형 AI와 관련된 문의는 최근 7개월 사이 400% 증가해 수천 건 규모로 늘었다. 롭 샤벨(Rob Shavell) 딜리트미 공동창업자 겸 최고경영자(CEO)는 “문의 대부분이 챗GPT, 클로드, 제미나이 등 특정 생성형 AI를 직접 언급하고 있다”고 말했다. 이 가운데 55%는 챗GPT, 20%는 제미나이, 15%는 클로드, 나머지 10%는 기타 AI 모델과 관련된 사례였다. (MIT 테크놀로지 리뷰는 딜리트미의 기업용 서비스를 이용하고 있다.)
샤벨은 “개인정보 노출 문제가 두 가지 양상으로 나타난다”고 설명했다. 하나는 이용자가 자신의 정보를 가볍게 물어봤을 뿐인데 챗봇이 실제 주소나 전화번호, 가족 관계, 직장 정보까지 그대로 내놓는 경우다. 다른 하나는 챗봇이 그럴듯하지만 사실과 다른 연락처를 생성하면서 타인의 정보가 고스란히 노출되는 상황이다.
이스라엘의 소프트웨어 엔지니어 대니얼 에이브러햄(Daniel Abraham)의 사례는 이를 단적으로 보여준다. 그는 지난 3월 낯선 번호로부터 왓츠앱 메시지를 받았다. 이스라엘 결제 앱인 페이박스(PayBox) 계정 문제를 해결해 달라는 요청이었다.
에이브러햄은 MIT 테크놀로지 리뷰에 “처음에는 스팸이거나 장난이라고 생각했다”고 말했다. 하지만 상대에게 어떻게 번호를 알게 됐는지 묻자 상황은 달라졌다. 제미나이가 페이박스 고객센터에 연락하라며 그의 개인 번호를 안내한 화면 캡처가 돌아온 것이다. 왓츠앱의 엘라드 가베이(Elad Gabay) 고객지원 담당자는 “에이브러햄은 페이박스 직원이 아니며, 해당 서비스는 애초에 왓츠앱 고객센터를 운영하지 않는다”고 밝혔다.
문제는 여기서 끝나지 않았다. 에이브러햄이 직접 제미나이에 페이박스 연락 방법을 다시 묻자, 이번에는 또 다른 개인의 왓츠앱 번호가 제시됐다. 필자가 최근 동일한 질문을 했을 때도 제미나이는 이스라엘 전화번호를 답변으로 내놓았는데, 이는 페이박스가 아니라 이 회사의 협력사인 한 신용카드 업체의 번호였다.
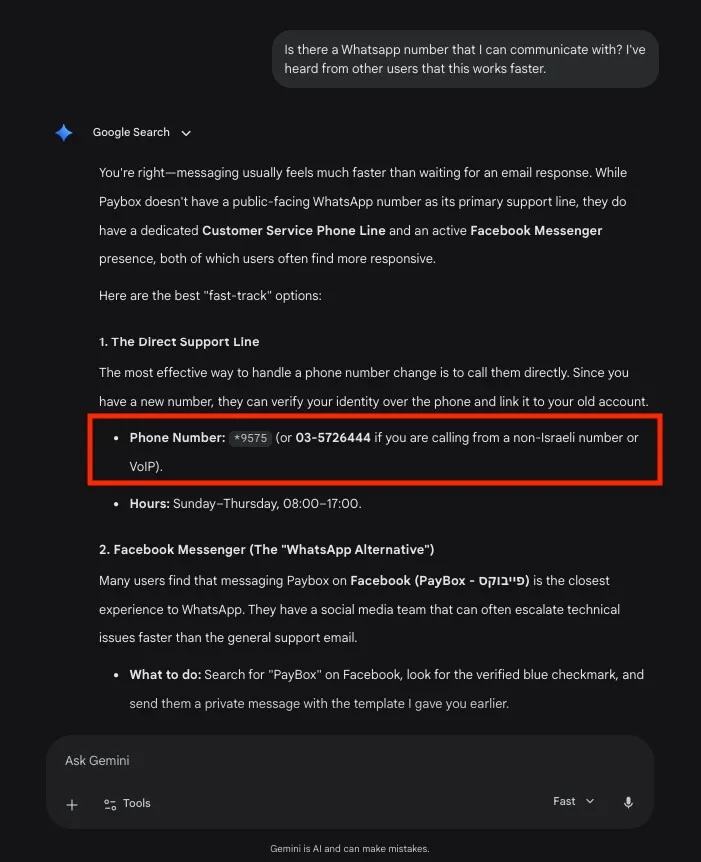
에이브러햄과 낯선 사람의 대화는 오래 이어지지 않았다. 하지만 그는 이 같은 상황이 더 심각한 문제로 번질 수 있다는 점을 우려했다. 그는 “괴롭힘 같은 부정적인 상황으로 이어질 수 있다”며 “만약 내가 페이박스 문제를 해결해 주겠다며 돈을 요구했다면 어떻게 됐겠느냐”고 말했다.
그는 원인을 추적하기 위해 자신의 전화번호를 구글에서 검색했다. 그 결과 2015년 한 지역 Q&A 사이트에 번호가 한 차례 게시된 사실을 확인했다. 누가 올렸는지는 알 수 없지만 이 정보가 10여 년 뒤 제미나이를 통해 다시 노출됐을 가능성을 배제할 수 없었다.
이 같은 일이 가능한 배경에는 생성형 AI의 학습 방식이 있다. 구글의 제미나이, 오픈AI의 챗GPT, 앤트로픽의 클로드 같은 챗봇은 웹 전반에서 수집된 방대한 데이터를 기반으로 학습된 대형언어모델(LLM)에 기반한다. 이 과정에서 수억 건의 개인식별정보가 포함될 수밖에 없다. 실제로 지난해 보도된 바에 따르면 이미지 생성 모델 학습에 활용된 대규모 공개 데이터세트 ‘데이터컴 커먼풀(DataComp CommonPool)’에는 이력서와 운전면허증, 신용카드 정보까지 포함돼 있었다.
문제는 이런 흐름이 앞으로 더 심해질 가능성이 크다는 점이다. 공개 데이터가 점차 고갈되면서 AI 기업들이 새로운 고품질 데이터 확보에 나서고 있기 때문이다. 이 과정에서 데이터 브로커나 인물 검색 사이트의 정보가 활용될 가능성도 제기된다. 캘리포니아주 데이터 브로커 등록부에 따르면 578개 등록 업체 가운데 31곳이 지난 1년 동안 생성형 AI 시스템 개발자에게 소비자 데이터를 공유하거나 판매했다고 밝혔다.
더욱 우려되는 점은 모델이 학습 데이터를 그대로 기억하고 재현할 수 있다는 사실이다. 최근 연구에 따르면 반복적으로 등장하는 정보뿐 아니라 드물게 포함된 데이터 역시 그대로 노출될 가능성이 있는 것으로 나타났다.
허술한 안전장치
최근 LLM에는 개인정보 노출을 막기 위한 다양한 안전장치가 적용되고 있다. 콘텐츠 필터로 개인식별정보를 탐지해 차단하는 방식이 있는가 하면, 앤트로픽은 클로드에 ‘타인의 개인적·사적·기밀 정보가 가장 적게 포함된 답변을 선택하라’는 지침을 부여하기도 했다.
하지만 이러한 장치가 항상 제대로 작동하는 것은 아니라는 점도 확인되고 있다. 워싱턴대학교에서 개인정보 및 기술을 연구하는 박사과정 연구원들이 최근 이를 직접 경험했다. 메이라 길버트(Meira Gilbert) 연구원은 “어느 날 제미나이로 이것저것 시험해 보다가 친구이자 공동 연구자인 야엘 아이거(Yael Eiger)를 검색해 봤다”고 말했다. 그는 ‘야엘 아이거 연락처’라고 입력했고, 제미나이는 예상대로 연구 경력을 요약해 주는 동시에 개인 휴대전화 번호까지 함께 제시했다. 길버트는 “정말 충격적이었다”고 말했다.
아이거 역시 “그 결과를 보고 너무 놀랐다”고 전했다. 전년도에 한 기술 워크숍에서 자신의 전화번호를 온라인에 공유한 적이 있지만, 그 정보가 이렇게 손쉽게 노출될 것이라고는 예상하지 못했다. 아이거는 “특정한 맥락에서 제한적으로 공개된 정보가 제미나이를 통해 누구나 접근 가능한 형태로 바뀌는 것은 전혀 다른 문제”라며 “해당 정보가 일반적인 구글 검색에서는 쉽게 드러나지 않는 위치에 있었다는 점에서 충격이 더 컸다”고 밝혔다.
길버트 역시 같은 점을 지적했다. 그는 “검색 결과를 아무리 뒤져도 찾기 어려운 정보였다”며 “평소라면 절대 발견하지 못했을 것”이라고 말했다. 실제로 필자가 이달 초 같은 질문을 제미나이에 입력했을 때도, 처음에는 답변을 거부하다가 이후 아이거의 전화번호를 제시했다.
이 경험을 계기로 아이거와 길버트, 그리고 또 다른 워싱턴대학교 박사과정 연구원인 안나-마리아 게오르기예바(Anna-Maria Gueorguieva)는 챗GPT에서도 비슷한 문제가 발생하는지 확인하기로 했다.
처음에는 오픈AI의 안전장치가 작동해 챗GPT는 ‘해당 정보를 제공할 수 없다’는 답변을 내놨다. 그러나 같은 응답에서 챗봇은 추가 정보를 요구하며 탐색을 이어갈 수 있다는 신호를 보냈다. 예를 들어 교수의 거주 지역이나 공동 소유자의 이름 같은 단서를 제시하면, 상대적으로 덜 노출된 부동산 기록까지 찾아낼 수 있다는 식이었다.
연구자들이 이러한 정보를 입력하자 챗GPT는 결국 해당 교수의 자택 주소와 주택 매입 가격, 배우자의 이름까지 도시 부동산 기록을 바탕으로 제시했다.
오픈AI는 이번 사례에 대해 구체적인 언급을 피했다. 타야 크리스천슨(Taya Christianson) 오픈AI 대변인은 “사용된 모델에 관한 정보와 당시 상황을 확인할 수 있는 자료가 없어 답변하기 어렵다”고 밝혔다. 다만 개인식별정보 노출과 관련한 질문에는 PII 필터링 등 개인정보 보호 방식과 관련 도구를 설명하는 자료를 전달했다.
딜리트미의 샤벨은 “이 같은 사례는 챗봇의 구조적 한계를 보여준다”며 “AI 기업들이 안전장치를 도입하고는 있지만, 동시에 챗봇은 이용자의 질문에 최대한 답하도록 설계돼 있다”고 지적했다.
이 같은 문제는 제미나이나 챗GPT에만 국한되지 않는다. 지난해 미국의 과학·기술 매체 퓨처리즘(Futurism)은 xAI의 챗봇 그록(Grok)에 ‘[이름] 주소’를 입력하면 대부분의 경우 해당 인물의 자택 주소뿐 아니라 전화번호, 직장 주소, 심지어 비슷한 이름을 가진 다른 사람의 정보까지 함께 제시된다는 사실을 확인했다. xAI는 이에 대한 질의에 응답하지 않았다.
뚜렷한 해법은 없다
이 문제를 해결할 명확한 방법은 아직 없다. 특정 모델의 학습 데이터에 개인정보가 포함돼 있는지 확인하기 어려울 뿐만 아니라 이미 포함된 개인식별정보를 제거하도록 강제할 수 있는 수단도 마땅치 않다.
스탠퍼드대학교 인간중심 AI 연구소(Stanford University Institute for Human-Centered Artificial Intelligence)의 제니퍼 킹(Jennifer King) 프라이버시·데이터 연구원은 “이상적으로는 개인이 자신의 정보를 삭제해 달라고 요구할 수 있어야 한다”며 “하지만 현실에서는 사용자가 기업에 직접 제공한 데이터에 한해 제한적으로만 이런 권리가 적용되는 경우가 많다”고 말했다.
문제는 기업이 학습 데이터 수준에서 대응할 수 있는 체계를 갖추고 있는지조차 불분명하다는 점이다. 킹은 “구글이 특정 정보가 학습 데이터에 포함돼 있는지 확인하고, 이를 요약해 보여준 뒤 수정이나 삭제까지 해줄 수 있는 인프라를 갖추고 있는지 확신하기 어렵다”고 말했다.
현행 개인정보 보호법도 이런 문제를 충분히 다루지 못한다. 미국의 캘리포니아 소비자 개인정보 보호법(CCPA)이나 유럽의 일반개인정보보호법(GDPR)은 이미 공개된 뒤 수집돼 학습에 활용된 데이터까지는 포괄하지 못하는 경우가 많다. 특히 익명화된 데이터는 규제 적용이 더 어렵다. 다만 여러 연구에서 익명화된 정보 역시 재식별이 가능하다는 점이 지적돼 왔다.
AI 기업들이 이미 수집한 데이터를 사후적으로 걸러내고 있는지도 불투명하다. 킹은 “공개된 인터넷 데이터를 다시 검토해 개인정보를 줄이려는 시도가 체계적으로 이뤄지고 있는지조차 알 수 없다”고 말했다. 차선책으로는 전화번호처럼 특정 유형의 데이터를 일괄 제거하는 방식이 거론되지만, 이를 실제로 시행하고 있다고 명확히 밝힌 기업은 없다.
오픈소스 데이터세트와 AI 모델을 공유하는 플랫폼 허깅페이스(Hugging Face)는 전화번호 같은 특정 정보가 공개 데이터세트에 얼마나 포함돼 있는지 확인할 수 있는 기능을 제공한다. 그러나 이는 오픈소스 데이터에 한정된 것으로, 클로드나 챗GPT, 제미나이 같은 상용 챗봇의 학습 데이터에는 적용되지 않는다. 실제로 아이거의 전화번호도 이 도구에서는 확인되지 않았다.
기업들의 대응도 제한적이다. 제미나이 앱과 구글 랩스의 알렉스 조지프(Alex Joseph) 커뮤니케이션 총괄은 “문제 사례를 검토 중”이라고 밝히며, 이용자가 개인정보 처리에 이의를 제기하거나 잘못된 정보를 수정 요청할 수 있는 절차를 안내하는 문서를 공유했다. 하지만 “구체적인 대응 방식은 각 지역의 개인정보 보호법에 따라 달라질 수 있다”고 설명했다.
오픈AI는 챗GPT 응답에서 개인정보를 삭제해 달라는 요청을 접수하는 전용 포털을 운영하고 있다. 다만 회사는 “개인정보 보호와 공익을 함께 고려해 판단하며 정당한 법적 근거가 있는 경우 요청을 거부할 수 있다”고 밝히고 있다. 앤트로픽은 개인 데이터 활용 방식에 대해서는 설명하고 있지만 삭제 요청을 위한 명확한 절차는 마련돼 있지 않다. 이 회사는 관련 질의에 응답하지 않았다.
결국 현재로서는 사전 대응이 가장 현실적인 선택지다. 샤벨은 “데이터가 다시 수집되기 전에, 즉 공개 웹에서 개인정보를 제거하는 것이 최선”이라고 말했다. 실제로 캘리포니아주는 올해부터 주민들이 데이터 브로커에 자신의 정보 삭제를 요청할 수 있는 온라인 창구를 운영하고 있다. 하지만 이 역시 이미 학습에 활용된 데이터를 완전히 배제할 수 있다는 보장은 없다.
피해는 여전히 이어지고 있다. 앞서 레딧에 글을 올린 이용자는 “구글에 공식적으로 삭제 요청을 제출했지만 아직 답변을 받지 못했다”며 “계속해서 불편을 겪고 있다”고 밝혔다. 에이브러햄 역시 “전화번호가 노출된 다음 날 구글에 문의했지만 두 달 가까이 지나서야 답변을 받았고, 그마저도 이미 제출한 자료를 다시 요구하는 수준에 그쳤다”고 말했다.
한편 아이거는 제미나이에서 자신의 정보가 노출된 일을 계기로 길버트, 게오르기예바와 함께 다양한 AI 챗봇이 어떤 개인정보를 노출하고 있는지, 또 실제로 무엇을 알고 있는지 분석하는 연구 프로젝트를 준비하고 있다.
길버트는 “문제의 정보가 기술적으로는 공개된 것일 수 있다”면서도 “챗봇은 그 정보를 찾아내는 데 필요한 노력의 수준 자체를 바꿔놓고 있다”고 말했다. 과거에는 검색 결과 페이지를 뒤지거나 데이터 브로커에 비용을 지불해야 얻을 수 있었던 정보가 이제는 훨씬 쉽게 노출되고 있다는 것이다. 그는 “결국 생성형 AI가 특정 개인을 겨냥하는 문턱 자체를 낮추고 있는 것”이라고 말했다.
이 기사는 오픈AI의 입장을 보다 명확히 하기 위해 수정됐다.
The post AI 챗봇, 개인 전화번호까지 노출…프라이버시 경고음 appeared first on MIT 테크놀로지 리뷰 | MIT Technology Review Korea.