엔비디아, AI 추론을 넘어 에이전트 경제를 강화한다
AI 산업의 중심이 학습에서 추론으로 이동하면서, 엔비디아는 GPU·LPU·소프트웨어를 결합한 ‘에이전트 경제’ 인프라를 제시하고 있다.
최근 AI 산업이 버블이 아닌지 우려하는 목소리가 나올 때도 있다. 그러나 AI 산업의 성장이 예상을 훨씬 뛰어넘고 있다. 엔비디아는 최근 GPU 테크 컨퍼런스(MIT 경제학과 교수이자 2024년 노벨 경제학상 수상자인 대런 아세모글루(Daron Acemoglu)는 “AI 기술이 과대 포장되고 있으며, 우리가 마땅히 해야 할 수준 이상으로 투자하고 있다”고 경고한다. 무디스(Moody’s) 이코노미스트 마크 잔디(Mark Zandi) 역시 “AI가 역사상 가장 중요한 기술 중 하나가 될 수 있지만, 미래를 어떻게 형성할지에 대한 구체적 경로는 여전히 불확실하다”고 분석했다.
AI 산업이 과열됐다는 평가가 나오고 있지만, 엔비디아는 정반대의 메시지를 내놓고 있다. 젠슨 황(Jensen Huang) CEO는 3월 17일(현지시간) 미국 새너제이에서 열린 GTC 2026 기조연설에서 2027년까지 AI 칩과 인프라 사업의 누적 주문이 최소 1조 달러에 달할 것이라고 전망했다. 지난해 발표한 약 5,000억 달러 예측의 두 배다. 젠슨 황 CEO는 “사실 우리는 부족할 것이다. 컴퓨팅 수요가 그보다 훨씬 클 것이라고 확신한다”고 덧붙였다.
이 전망의 핵심 근거는 ‘추론(inference)’ 수요의 폭발적 증가다. 황 CEO는 이를 “추론 변곡점(inference inflection)”이라고 규정하며, AI 산업이 학습 중심에서 실제 서비스 중심으로 이동하고 있다고 강조했다.
이 변화의 본질은 단순한 워크로드 이동이 아니다. AI가 단순히 답변을 생성하는 단계를 넘어, 스스로 작업을 수행하는 ‘에이전트(agent)’ 형태로 진화하면서, 인프라 설계와 비용 구조, 그리고 산업의 경쟁 방식 자체가 바뀌고 있다. 이번 GTC 2026에서 엔비디아가 제시한 것은 이러한 에이전트 경제를 지탱하기 위한 전체 스택의 재구성이었다.
메모리 기술이 AI 추론 경쟁의 핵심인 루빈 울트라
GTC 2026에서 공개된 베라 루빈(Vera Rubin) 플랫폼은 차세대 AI 데이터센터의 핵심 인프라로 자리매김할 전망이다. 루빈 GPU 72개와 베라 CPU 36개를 결합한 NVL72 랙 시스템은 130만 개의 부품으로 구성되며, 전작 그레이스 블랙웰 대비 와트당 추론 성능이 10배 향상됐다고 엔비디아는 주장한다. 트레이닝에서도 동급 규모의 MoE(Mixture-of-Experts) 모델을 블랙웰 대비 4분의 1 수준의 GPU로 학습할 수 있으며, 토큰당 생성 비용은 10분의 1로 줄어든다. 이미 마이크로소프트와 메타가 초기 샘플을 수령하고 5배 추론 성능 향상을 확인한 것으로 알려졌다.
시스템 아키텍처 측면에서 루빈 울트라(Rubin Ultra)는 기존의 단일 GPU 구조를 넘어 4개의 대형 GPU 다이(Die)를 하나로 묶는 칩렛(Chiplet) 기반 설계를 채택했다. 약 5,000억 개의 트랜지스터에 384GB HBM4e 메모리, 32TB/s 대역폭을 탑재한다. FP4 기준 약 100페타플롭스 수준의 성능을 제공하며, NVLink 7세대 인터페이스는 루빈 대비 6배 빠른 1.5PB/s의 처리량을 구현한다. 하나의 GPU 패키지가 소형 AI 클러스터처럼 동작하며, GPU의 개념 자체를 독립적 컴퓨팅 유닛으로 끌어올렸다.

이러한 GPU는 트레이(Tray)와 랙(Rack) 단위로 확장되어 하나의 거대한 AI 팩토리를 구성한다. 황 CEO가 새로 공개한 카이버(Kyber) 랙 아키텍처는 수직형 컴퓨트 트레이로 144개 GPU를 집적해 밀도와 지연시간을 동시에 개선하며, 루빈 울트라에서는 NVL576으로 확장해 576개 GPU 다이를 단일 NVLink 도메인으로 연결한다. 엔비디아는 이미 이후 세대인 파인만(Feynman) 아키텍처(2028년 목표)까지 로드맵을 공개했으며, 우주 기반 AI 데이터센터 모듈까지 시연했다.
하지만 이와 같은 성능을 구현하기 위해서는 전력과 냉각 구조가 근본적으로 변화해야 한다. 루빈 울트라 기반 랙은 메가와트(MW) 단위의 전력을 요구하며, 베라 루빈 플랫폼은 전면 액체 냉각을 도입했다. 엔비디아는 2027년부터 800V 고압 직류(HVDC) 아키텍처로 전환할 계획이다. 황 CEO는 AI를 ‘5겹 케이크’에 비유하며 에너지를 그 기초 층으로 꼽았다. GTC 2026 행사장 인근에서 그린피스 미국 지부가 글로벌 공급망의 재생에너지 전환을 촉구하는 시위를 벌였고, 반도체 전문 리서치 기관 세미애널리시스(SemiAnalysis)는 연간 EUV 장비 생산량이 약 70대에 불과한 현실을 지적하며 2030년까지 글로벌 AI 컴퓨팅이 물리적 한계에 도달할 수 있다고 경고했다. 모건스탠리는 빅테크 기업들이 2028년까지 AI 인프라에 약 3조 달러를 투자할 것으로 예상하면서, 자체 현금흐름으로는 그 절반만 충당 가능하다고 분석했다.
1TB급 HBM4e의 등장은 AI 경쟁의 핵심 병목을 GPU 연산 성능에서 메모리 기술로 이동시키고 있으며, 이 메모리를 누가 공급하느냐가 산업의 경쟁 구도를 재편할 변수로 부상했다. 그간 HBM3 시장에서 SK하이닉스가 60% 이상의 점유율로 독주해왔으나, 차세대 HBM4에서는 삼성전자가 선제적으로 엔비디아에 칩을 공급하며 판세를 뒤흔들고 있다. 삼성전자는 GTC 전시에서 HBM4와 함께 차세대 HBM4E(핀당 16Gbps, 대역폭 4TB/s) 실물 칩을 최초 공개했다. 인사이트코리아에 따르면 황 CEO가 지난달 SK하이닉스 임직원들과의 비공식 자리에서 “경쟁이 없는 환경이 우려스럽다”고 말한 것은 공급망 다변화 전략의 일환으로, TSMC-SK하이닉스-엔비디아의 기존 ‘삼각 동맹’에 삼성전자가 메모리 측면에서 균열을 내고 있는 셈이다.
토큰당 비용과 응답 지연을 줄이는 그록칩3 LPX 공개
이번 GTC 2026의 가장 전략적인 발표 중 하나는 그록(Groq) 3 LPU와 LPX 랙 시스템이다. 이는 엔비디아가 2025년 12월 크리스마스 이브에 약 200억 달러 규모의 자산 인수를 통해 확보한 기술로, 엔비디아 역사상 최대 규모의 거래다. 그록은 구글 내부 TPU의 원 설계자로 알려진 조나선 로스(Jonathan Ross)가 창업한 회사로, 로스와 선임 리더들은 현재 엔비디아에 합류해 기술 확장을 주도하고 있다.
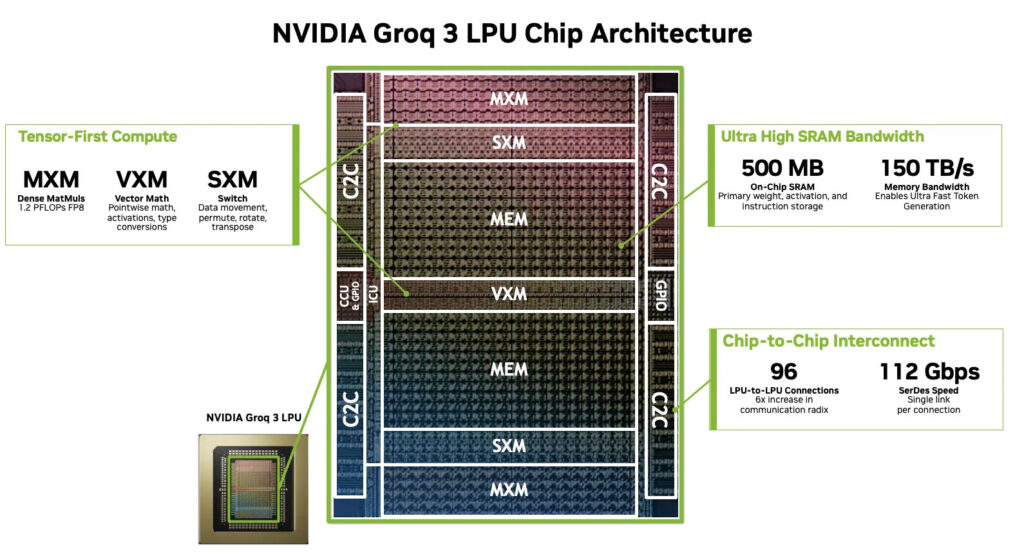
그록 3 LPU는 삼성전자 파운드리의 4nm(SF4X) 공정으로 제조된다. 황 CEO는 기조연설에서 “우리를 위해 그록 칩을 생산해 준 삼성에 감사한다”고 공개적으로 언급했는데, 삼성전자가 파운드리를 통해 엔비디아에 AI 칩을 공급하는 것은 2020년 RTX 3000 시리즈 이후 처음이다. 카운터포인트리서치의 제이크 라이(Jake Lai)는 이를 “대형 AI 칩 제조 역량을 입증한 사례”로 평가했다. 대만 시장조사 기관 트렌드포스(TrendForce)에 따르면 삼성은 양산을 위해 웨이퍼 생산량을 약 9,000장에서 15,000장으로 확대한 것으로 알려졌다. 다만 엔비디아의 핵심 GPU인 루빈 시리즈는 여전히 TSMC에서 제조되며, 삼성 파운드리 점유율이 2024년 2분기 10%에서 2025년 4분기 7%로 하락한 상황에서 이번 수주가 반등의 기점이 될 수 있을지가 관건이다.
기술적으로 그록 3 LPU는 GPU 중심 구조와 달리 초저지연 추론에 특화된 LPU(Language Processing Unit) 아키텍처를 채택했다. DRAM 대신 온칩 SRAM 중심 구조로 메모리 병목을 최소화한 것이 핵심이다. 각 LP30 다이에 512MB의 온칩 SRAM이 탑재되어 150TB/s의 메모리 대역폭을 제공하는데, 이는 루빈 GPU의 HBM4가 제공하는 22TB/s를 크게 상회한다. LPX 랙은 256개의 LPU를 통합하며, 128GB의 온칩 SRAM, 40PB/s 이상의 대역폭과 640TB/s의 칩 간 연결 대역폭을 제공한다.
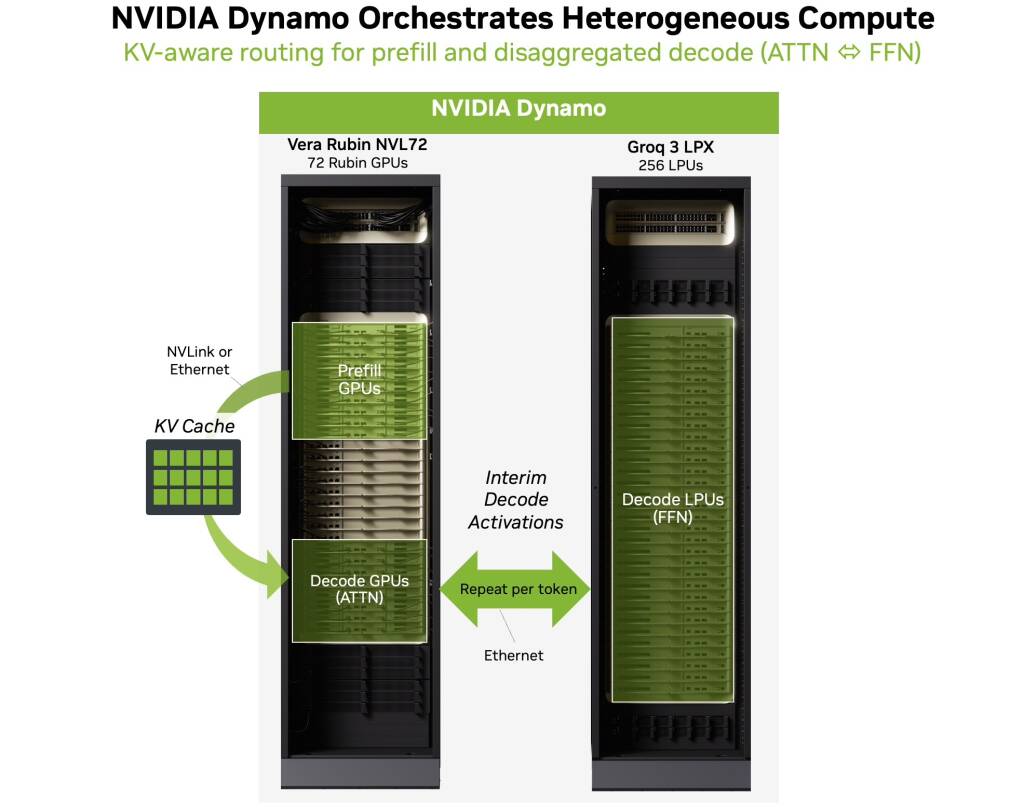
이 그록 3 LPX는 베라 루빈 NVL72와 공동 설계돼 하나의 통합된 AI 팩토리 구조를 구성한다. 엔비디아가 ‘이기종 추론(Heterogeneous Inference)’이라 부르는 이 패러다임에서, 루빈 GPU는 긴 입력 컨텍스트를 처리하는 프리필(prefill) 단계를, 그록 LPU는 출력 토큰을 빠르게 생성하는 디코드(decode) 단계를 각각 맡는다. 골드만삭스는 이 조합이 메가와트당 추론 처리량을 35배 향상시키며, 조(兆) 단위 파라미터 모델의 토큰 생성 비용을 백만 토큰당 약 45달러 수준으로 끌어내려 10배 이상의 수익화 공간을 창출한다고 분석했다. 황 CEO는 “클라우드 사업자들이 더 많은 용량만 확보할 수 있다면, 더 많은 토큰을 생성할 수 있고, 그러면 매출이 올라간다”고 말했다.
다만 추론 시장에서 엔비디아의 지위는 학습 시장만큼 견고하지 않다. 학습 시장에서 약 90%의 점유율을 차지하는 반면, 추론 시장에서는 60~75% 수준이며 커스텀 실리콘과의 경쟁이 빠르게 심화되고 있다. 구글의 7세대 TPU 아이언우드(Ironwood)는 와트당 성능에서 블랙웰에 필적한다는 평가를 받고 있고, 세미애널리시스 팀조차 ‘구글의 실리콘 우위는 하이퍼스케일러 중 타의 추종을 불허한다’고 인정했다. 아마존은 트레이니엄(Trainium) 3를 2026년 초부터 배포 중이고, AMD는 오픈AI와 총 6기가와트 규모의 GPU 공급 계약을 체결해 2026년 하반기부터 MI450 1기가와트를 우선 배치할 예정이다. 미국 투자은행 DA 데이비슨(DA Davidson)의 알렉스 플랫(Alex Platt) 애널리스트는 그록의 낮은 메모리 용량을 지적하며 “그록의 현재 기술은 추론 워크로드의 작은 하위 집합에만 적용 가능하다“고 평가해, 200억 달러 인수의 검증이 아직 끝나지 않았음을 시사했다.
대규모 AI 추론 최적화를 위한 차세대 운영체제, 다이나모
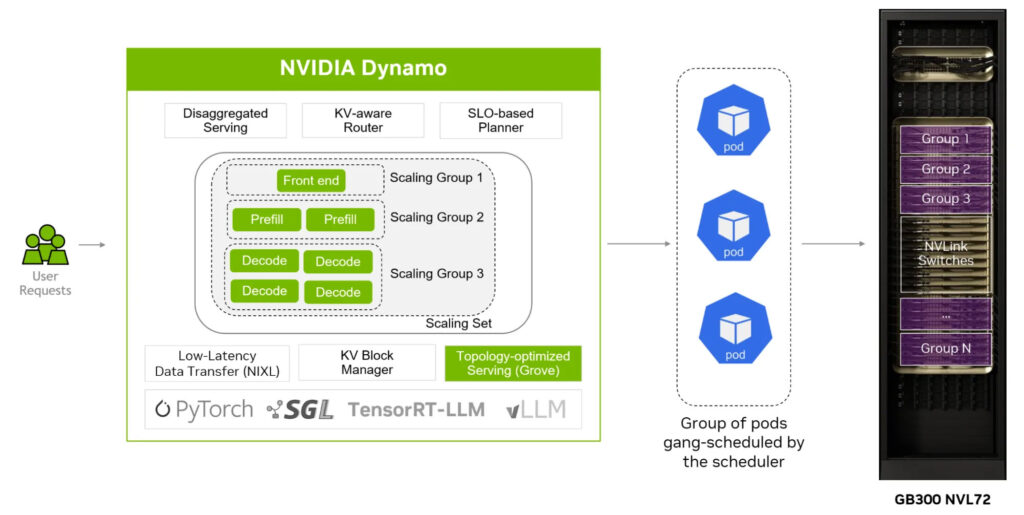
AI 팩토리의 핵심 운영체제(OS)로 출시된 다이나모(Dynamo) 1.0은 대규모 생성형 AI 추론을 최적화하기 위한 프로덕션 환경 중심의 시스템 소프트웨어 스택이다. 세미애널리시스는 다이나모가 기존 오픈소스 추론 프레임워크인 vLLM과 SGLang을 대체할 잠재력이 있다고 평가하면서, 이들이 제공하지 못하는 기능을 다수 구현하면서도 더 높은 성능을 달성한다고 분석했다.
다이나모의 핵심은 수백만 개의 GPU를 하나의 거대한 생산 시스템처럼 운영하며 토큰 생성 비용 최적화, 처리량 극대화, 지연시간 최소화를 동시에 달성하는 것이다. 스마트 라우터(Smart Router)가 다중 GPU 배포 환경에서 각 토큰을 프리필과 디코드 GPU에 지능적으로 분배하며, 블랙웰 기반 환경에서 최대 7배의 성능 향상을 제공한다. 랭체인(LangChain), vLLM, TensorRT-LLM, SGLang 등 주요 프레임워크와 네이티브로 연동되며, 엔비디아 그로브(Grove)는 쿠버네티스(Kubernetes) 환경에서 토폴로지 인식 워크로드 배포를 간소화하는 오픈소스 API를 제공한다.
그러나 ‘오픈소스’라는 표현에는 주의가 필요하다. 다이나모는 코드 자체는 공개하지만, 최적화의 핵심 성능은 엔비디아 하드웨어, NVLink 패브릭, NVFP4 연산 유닛, 그록 LPU와의 이기종 분업 구조에 깊이 의존한다. vLLM이 UC 버클리 연구팀에서 출발해 벤더 중립적 생태계를 유지해왔다면, 다이나모의 성능 우위는 사실상 엔비디아 하드웨어를 전제한다. IT 산업 분석 기관 퓨처럼 그룹(Futurum Group)의 분석에 따르면, GTC에서 제시된 이기종 추론 전략은 다이나모 없이는 작동하지 않으며, 이는 고객의 하드웨어 선택권을 사실상 제약하는 효과를 가진다.
이미 알리바바 클라우드, AWS, 구글 클라우드, 마이크로소프트 애저, 오라클 클라우드 등 하이퍼스케일러뿐 아니라 코어위브(CoreWeave), 네비우스(Nebius), 투게더AI 등 AI 특화 사업자들도 다이나모 생태계에 참여하고 있다. 퍼플렉시티, 커서 등 AI 네이티브 기업과 아스트라제네카, 블랙록, 바이트댄스 등 글로벌 엔터프라이즈도 채택 중이다. 네비우스와 메타 간의 270억 달러 인프라 계약이 GTC에서 동시에 발표된 것은 플랫폼에 대한 산업의 신뢰를 보여준다. 그러나 IT 리서치 기관 컨스텔레이션 리서치(Constellation Research)의 래리 디그넌(Larry Dignan)은 “엔비디아가 스택의 상위로 올라갈수록 자사의 생태계 파트너들과 경쟁하게 될 것“이라고 지적했다. 하이퍼스케일러들의 커스텀 ASIC 출하량이 2026년에 44.6% 성장하는 반면 GPU 출하량은 16.1% 성장에 그칠 것이라는 트렌드포스의 전망은 이 긴장이 단순한 우려가 아님을 보여준다.
기업 환경에 적합한 안전한 에이전트 구현을 위한 니모클로
2026년 초, AI 산업 전체를 흔든 것은 하나의 사이드 프로젝트였다. 오스트리아 출신 개발자 페터 슈타인베르거(Peter Steinberger)가 1월에 출시한 오픈클로(OpenClaw)는 깃허브(GitHub) 역사상 가장 빠르게 성장하는 저장소 중 하나로 떠올랐다. 슈타인베르거는 이후 오픈AI에 합류했고, 샘 올트먼(Sam Altman) CEO는 오픈클로가 “오픈소스 프로젝트로서 재단 안에 존속하며, 오픈AI가 계속 지원할 것”이라고 밝혔다. 그러나 오픈클로의 빠른 성장 이면에는 명확한 한계가 존재했다. 어떤 API를 호출할 수 있는지, 어떤 데이터에 접근할 수 있는지, 그 행동을 어떻게 통제할 것인지에 대한 정책이 부재한 상태에서 기업 환경에서는 사용할 수 있는 기반이 마련되어 있지 않았다.
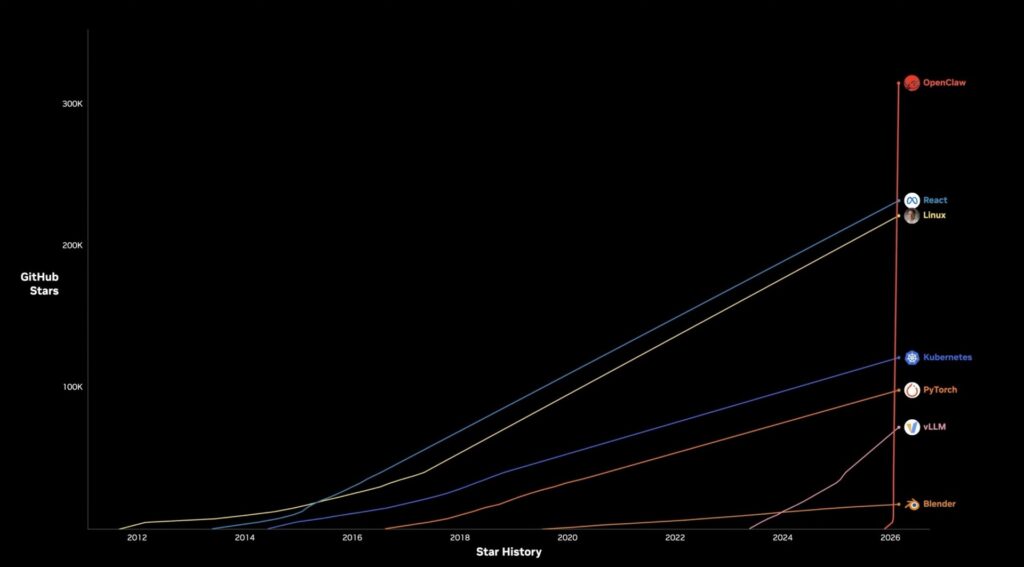
그러나 이 놀라운 속도의 이면에는 명확한 한계가 존재했다. 오픈클로는 강력한 에이전트 실행 능력을 갖추고 있었지만, 기업 환경에서 필수적인 보안과 통제 체계는 거의 갖추지 못한 상태였기 때문이다. 어떤 API를 호출할 수 있는지, 어떤 데이터에 접근할 수 있는지, 그리고 그 행동을 어떻게 추적하고 통제할 것인지에 대한 정책이 부재한 상황에서, 기업 입장에서는 이 에이전트를 신뢰하고 사용할 수 있는 기반이 마련되어 있지 않았다.
이 지점에서 엔비디아는 문제를 전혀 다른 각도에서 바라봤다. 에이전트의 경쟁력은 단순한 지능이나 성능이 아닌 안전하게 행동을 제한하고 통제할 가능성과 정도에 달려 있다는 것이다. 이러한 인식 아래 등장한 것이 니모(NeMo, 엔비디아가 만든 AI 모델 개발을 위한 오픈소스 프레임워크를 말함) 기반의 확장인 니모클로(NemoClaw)이다.
기술적으로 좀더 접근하자면, 기존의 ‘자율적이지만 위험한 에이전트’를 ‘통제 가능한 디지털 워커’로 전환시켰다. 니모클로의 핵심은 오픈클로의 자유로운 실행 능력 위에 정책 기반 보안 통제를 덧씌웠다. 기존 오픈클로는 강력한 자율성과 확장성을 제공했지만, 파일 접근 및 네트워크 연결, 외부 API 호출 등에서 통제가 부족해 기업 환경에서는 사용이 제한적이었다. 니모클로는 이를 보완하기 위해 NVIDIA 에이전트 툴킷을 결합하고, 그 안의 핵심 런타임인 오픈쉘(OpenShell, AI 에이전트 관리 및 상호작용을 위한 오픈소스 프레임워크로 에이전트의 정책 및 보안 관리를 통합적으로 지원하는 시스템)을 통해 에이전트의 모든 행동을 감시하고 제어한다.
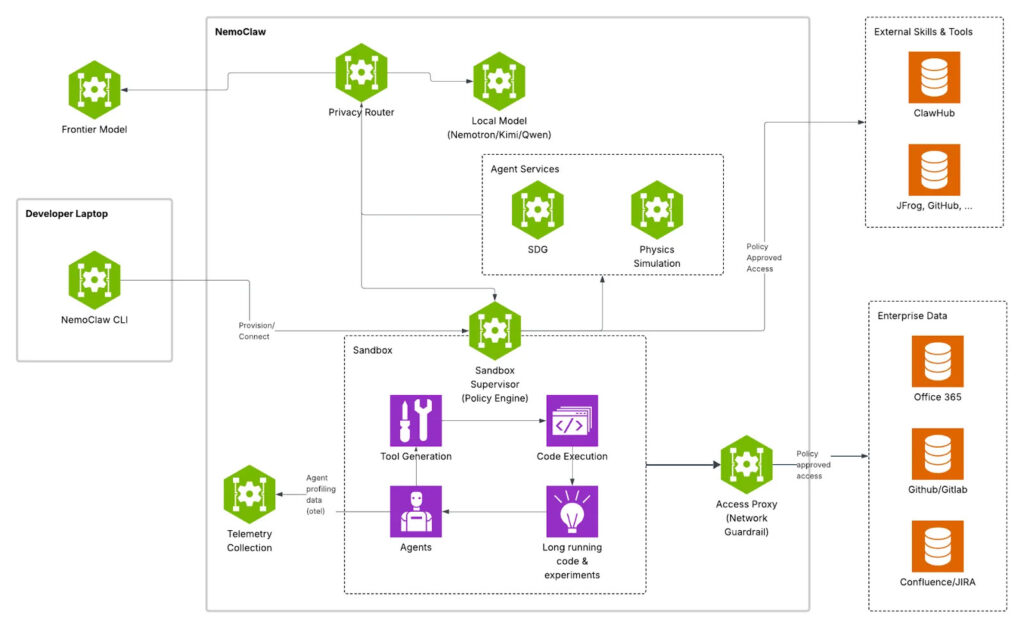
엔비디아는 이 문제를 정면으로 겨냥했다. 니모 기반의 확장인 니모클로는 오픈클로의 실행 능력 위에 정책 기반 보안 통제를 덧씌운 ‘AI 에이전트 운영체제’에 가깝다. 황 CEO는 기조연설에서 니모클로를 리눅스에 비유했다. 핵심 런타임인 오픈쉘이 에이전트의 모든 행동을 감시하고 제어하며, 프라이버시 라우터(Privacy Router)는 민감한 기업 데이터를 로컬에서 처리하고 일반적인 추론은 클라우드 모델을 활용하는 하이브리드 구조를 가능케 한다. 니모트론(Nemotron) 오픈 모델과 결합해 폐쇄형 모델 의존도를 낮추면서도 데이터 주권을 확보하는 전략이다.
이 전략의 이면에는 구글, 아마존, 마이크로소프트, 메타, OpenAI까지 자체 칩 개발에 총 500억 달러 이상을 투자하고 있는 상황에서, 하드웨어 이탈을 소프트웨어 락인(lock-in)으로 방어하려는 계산이 깔려 있다. 고성능 컴퓨팅 전문 매체 HPCwire의 취재에 따르면 한국 AI 추론 인프라 기업 프렌들리AI(FriendliAI) 창업자 전병곤은 “엔비디아가 생태계와 소프트웨어 스택 덕분에 2026년에도 지배적 위치를 유지할 것”이라 평가하면서도, AMD의 MI400 시리즈와 ROCm의 성숙이 변수가 될 수 있다고 덧붙였다.
결론적으로, GTC 2026에서 엔비디아가 제시한 그림은 일관된다. 루빈 울트라와 카이버 랙으로 하드웨어 밀도를 극대화하고, 그록 3 LPX로 추론 지연시간을 최소화하며, 다이나모로 소프트웨어 효율을 끌어올리고, 니모클로로 에이전트 시대의 기업 신뢰를 확보한다. 이 모든 것을 관통하는 핵심 개념은 ‘토큰 경제(Token Economy)’다. 오늘날 대부분의 AI 서비스는 토큰 단위로 과금되며, 오픈AI의 GPT-4o는 출력 100만 토큰당 10달러, 앤트로픽의 Claude Sonnet은 15달러 수준이다. 글로벌 컨설팅 기업 딜로이트(Deloitte)의 보고서에 따르면, 추론이 전체 AI 연산에서 차지하는 비중은 2023년 3분의 1에서 2025년 절반, 2026년에는 3분의 2로 빠르게 확대되고 있다. 추론 특화 칩 시장만 2026년 500억 달러를 넘길 전망이다. 과거 클라우드가 ‘서버 시간’ 단위로 과금되던 시대는 ‘생성된 토큰’ 단위로 가치가 측정되는 시대로 이행하고 있다. 황 CEO가 “전 세계 모든 CEO가 자신의 사업을 ‘와트당 토큰’이라는 지표로 평가하게 될 것“이라 선언한 것은 이 전환을 집약한다. AI 인프라 투자는 이제 단순한 설비 투자가 아니라 ‘토큰 생산 능력’이라는 수익 자산에 대한 투자로 성격이 바뀌고 있다.
그러나 미국 컨설팅 기업인 퓨처럼 그룹이 짚었듯 이 ‘추론 변곡점’은 동시에 새로운 복잡성의 시작이기도 하다. 에너지 그리드의 물리적 한계, 커스텀 실리콘의 부상, 그리고 AI 서비스가 실제로 투자 대비 충분한 수익을 창출할 수 있는가라는 근본적 질문은 여전히 열려 있다. 업계 전문가들은 황 CEO가 AI 업계에서 유독 비판을 피해가는 것은 그가 여전히 ‘건설하는 엔지니어’로 인식되기 때문이다. 하지만 그 건축물의 규모가 커질수록, 구조적 안전성에 대한 질문 역시 커질 수밖에 없다.
이 글을 쓴 서진호 칼럼니스트는 현재 AI 경영학회 이사(https://aiba.or.kr/)로, 마이크로소프트에서 테크니컬 에반젤리스트를 역임했으며, HPE 아시아 퍼시픽 인도지역에서 HPC&AI 프리세일즈 아키텍트로 근무했다.
The post 엔비디아, AI 추론을 넘어 에이전트 경제를 강화한다 appeared first on MIT 테크놀로지 리뷰 | MIT Technology Review Korea.